
Recent Computer Science Faculty Hire Joins Center for Networked Systems
Arun Kumar Works on Advanced Analytics at Intersection of Data Management and Machine Learning
On April 3, Computer Science and Engineering (CSE) assistant professor Arun Kumar began teaching his first undergraduate course since joining the UC San Diego faculty in 2016. CSE 190D covers topics in database system implementation, and it’s a hands-on, systems-focused course and the first at UC San Diego to teach the systems guts of a relational database management system (DBMS).
“Faculty in our Database group hope that this course will eventually be mainstreamed as 132C,” said Kumar. “It would complete a solid triad of database courses for undergraduates covering principles, applications and, finally, implementation.”

Kumar joined CSE after completing his Ph.D. at the University of Wisconsin-Madison last summer, with a focus on datamanagement and analytics. His research explores the intersection of data management and machine learning (ML), an area increasingly called advanced analytics. He also aims to create a pipeline of students coming into this burgeoning field – and the subject of the first graduate course he taught, CSE 291, during the winter quarter. “Advanced analytics is a brand-new field and companies require a lot of talent in this space,” he observed. “The dearth of engineers who understand machine learning is staggering, and a lot of companies are offering large salaries for people who understand software engineering, data systems and machine learning under the now-famous job title — data scientist.”
Advanced analytics is also the subject of a presentation Kumar will give for the Center for Networked Systems (CNS) on Tuesday, April 11 at 1pm in room 4140 of the CSE Building. His talk, “Democratizing Distributed Advanced Analytics,” will explore large-scale data analytics using statistical machine learning and how they are becoming increasingly critical for many data-driven applications.
“The data management, machine learning and systems communities are working on scalable and fast implementations of ML algorithms,” said Kumar. “However, several orthogonal bottlenecks in the end-to-end process of building and deploying ML models for data analytics have largely been ignored, leading to wasted resources and poor productivity of data scientists.”
CNS’s newest member will introduce three new projects to his audience and he hopes to solicit critical feedback. Kumar also foresees more collaborations with CNS and other CSE faculty. With CSE Prof. Kamalika Chaudhuri, he is already collaborating on the issue of differential privacy for machine learning. He is also working with two other CNS members: CSE Prof. Tajana Rosing, on understanding the tradeoffs facing machine-learning algorithms in the Internet of Things; and CSE Prof. Ranjit Jhala, on applying program analysis to bring new data-driven optimizations to advanced analytics codebases. As for other collaborators in CSE, Kumar is collaborating with CSE Prof. Lawrence Saul and fellow new hire, CSE Prof. Ndapa Nakashole, on using speech recognition to improve database usability.
“A couple of my upcoming projects will involve working on top of popular, distributed machine learning and data-processing systems such as Spark and TensorFlow to exploit the massive parallelism they offer for new abstractions that I create,” said Kumar. “I suspect this will eventually get me digging into the internals of these networked systems and perhaps optimizing them for the workloads that I care about. This could involve publishing with CNS co-authors, so becoming a member of the center seemed a no-brainer.”
Kumar wants to make it easier and faster to build and use ML algorithms to analyze large and complex datasets. “My work over the next few years is going to focus on building tools, software and abstractions to make it easier to use machine learning in practice,” he predicted. “I want to do so from the perspective of the data scientist’s productivity, the runtime performance and research efficiency, as well as other issues such as privacy.”
Kumar notes that systems and ideas based on his dissertation and research at UW-Madison have been released as part of the MADlib open-source library, used internally by Facebook, LogicBlox and Microsoft, and shipped in products from EMC, IBM, Oracle and Cloudera. “It’s been nice to work with industry about the practical applications of my work,” he noted. ““The practical relevance of my work can impact what people do today and from them I can learn what the challenges tomorrow will be, and how we as computer-science researchers can stay one step ahead by anticipating what comes next.”
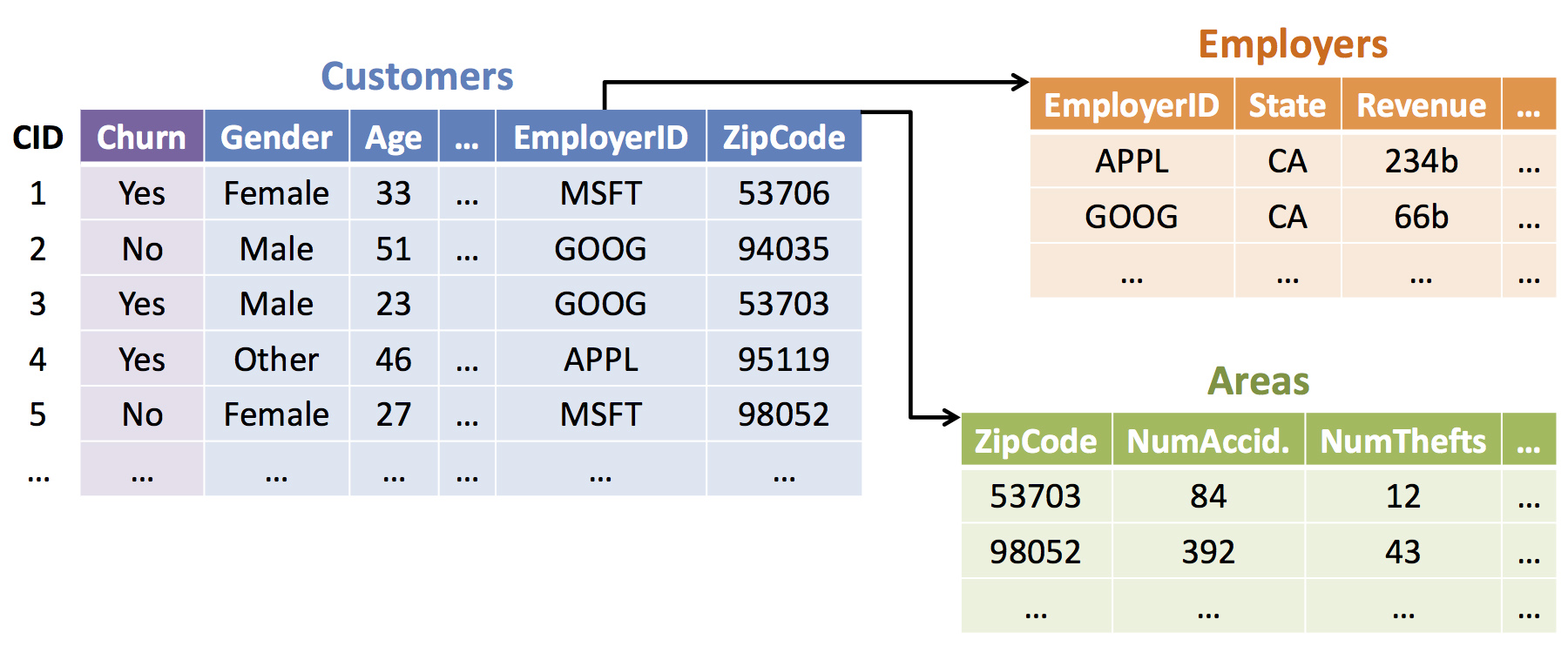
Kumar’s dissertation focused on training machine learning models based on data sets from multiple tables. “Data scientists usually combine all these tables into a massive single table,” he said. “These operations are called relational joins, and specifically key-foreign-key joins. Now the single table contains all the attributes of all the tables. This was the state of the art before I looked at this problem.”
Yet as Kumar confirmed, joining multiple tables together introduces redundancy into the data. “Consider a popular application of machine learning in enterprise domains: predicting customer churn,” he suggested. “You have a customers table joined with, say, a table about employers and another table about areas indexed by zip code. You could have a thousand customers employed by the same company, which means the record with the employer’s attributes (called its feature vector), gets repeated a thousand times after the join. The same could happen with the zip codes.” Result: the output of this join could be several times bigger than the input data. In one case at Microsoft, Kumar recalls, once they joined all their input tables for a Web security-related ML task to make one massive table, it blew up by a factor of ten. “A task that should have taken half an hour ended up taking a whole day on the cluster because the team overshot the storage space allotted to them — bringing down the shared cluster,” observed Kumar. “So storage becomes a major issue, as does the extra time wasted by the redundant computations performed by an ML algorithm over the redundant data.”
Kumar’s dissertation came up with two orthogonal new techniques. The first technique, called ‘avoiding the join physically,’ pushes down the machine learning computation to the input data in a multi-table format rather than having a single table with all the attributes. The challenge was to do so without affecting the accuracy of the ML model’s predictions. “That is a guarantee we provide and we have a proof for it,” confirmed Kumar. “Weff proved that the accuracy is unaffected. This mitigates the storage issue, because you don’t need the single table, and it mitigates the maintenance issue because you operate on the data as-is, and it mitigates the performance issue because you save a lot of runtime when you operate on the smaller input of the joins.”
One additional benefit of Kumar’s new paradigm: “Today many of the computations for machine learning happen in the cloud,” he said. “You purchase storage or computation runtime, and by reducing both, users can save a lot of money as well.”
The second part of his thesis focused on omitting unnecessary tables. “We showed that in many settings, for many ML models, some tables can be completely ignored,” explained Kumar. “We call it ‘avoiding the join logically’ because we are pretending that a table doesn’t even exist. If you omit a table, your runtime goes down, your storage goes down, and the data scientist’s productivity can go up because you have fewer tables and fewer attributes to manage.”
Kumar showed that prediction accuracy without the omitted table not only does not go down, but the runtime accelerates by two orders of magnitude – i.e., making the computation up to 100 times faster.
Among his many honors, Kumar received a 2016 Google Faculty Research Award, and the same year took home a graduate student research award from the University of Wisconsin for his dissertation research. He was also a recipient of the Best Paper award at SIGMOD 2014.
Kumar recognizes that he joined UC San Diego at an important turning point for anyone working in the general field of data science. CSE is about to launch its first major and minor in Data Science and Engineering, and the campus is developing a Data Science Institute thanks to a $75 million gift from CSE lecturer and alumnus Taner Halicioglu, announced last week. “I am excited that UC San Diego is taking data science seriously,” mused Kumar. “Democratizing data science is a grand challenge that transcends disciplines and requires bridging the gaps between the fields of data management, systems, machine learning, statistics, math, human-computer interaction, and several other fields, including myriad application domains. The generous gift from our alumnus is truly spectacular and I hope it will help accelerate UC San Diego’s research and education in this important area.”
Meantime, Kumar will focus on his teaching and research, and recruiting graduate students for his lab. Two M.S. students from his Winter 2017 course on advanced analytics are now working as research assistants in his group. “I had set a tough filter for enrollment: reviewing a research paper and answering some open-ended research questions,” he said. “This seems to have scared away many students but it ensured a high-quality atmosphere in class. Some of the students even managed to submit research papers on their course projects, one to KDD and another to a SIGMOD workshop, which has already been accepted, while two more are working on solidifying their work for submission to VLDB/SIGMOD. These are all top venues in this research area.”
In addition to teaching the undergraduate course on implementing relational database management systems, this Spring Kumar is also organizing a CSE 290 seminar for grad students on Advanced Data Science. For the seminar, students will read and present papers and articles on advanced data science applications and tools.
Related Links
Arun Kumar Website
Computer Science and Engineering, University of California San Diego
CSE 190 Topics in Database System Implementation
CSE 290 Seminar on Advanced Data Science
CSE 291 Topics in Advanced Analytics