
CNS and CSE’s Arun Kumar Works Toward Democratizing Deep Learning Systems
Deep learning (DL) is all around us: web search and social media, machine translation and conversational assistants, healthcare, and many other applications. DL is a resource-intensive form of machine learning (ML) that typically needs graphics processing units (GPUs), a lot of memory, and a computer cluster.
While large technology companies are amassing these resources, the status quo is far from ideal. DL is challenging to adopt for smaller companies, domain scientists, and others. As a result, there is a pressing need to rein in DL’s resource bloat, total costs, and energy consumption to truly democratize it for all users.

Kumar recently presented the team’s vision at the CIDR 2021 conference. The paper Cerebro: A Layered Data Platform for Scalable Deep Learning was co-authored with advisees Supun Nakandala, Yuhao Zhang, Side Li, Advitya Gemawat, and Kabir Nagrecha. The talk discussed Cerebro’s system design philosophy and architecture, recent research and open questions, initial results, and tangible paths to practical impact.
DL software systems specify, compile and execute DL training and prediction workloads on large datasets. Kumar’s team noticed a key missing piece: there is no analog to query optimization at scale, causing massive waste, high runtimes, and increased costs.
This is where their approach, called multi-query DL, comes into play. By reasoning more holistically about model building in DL, the team can enable new system optimizations at scale.
The vision is for Cerebro to elevate DL model building, exploration, and debugging with higher-level APIs that are already common. Examples include hyper-parameter tuning, neural architecture tuning, so-called AutoML procedures, and sub-group analysis. Under the hood, Cerebro exploits both the computational and the mathematical properties of the workload, as well as the data layout and hardware properties, to run it more efficiently.
Cerebro’s layered system design, called logical-physical decoupling, helps it infuse a series of novel systems optimizations into multiple DL tools (e.g., PyTorch or TensorFlow), execution environments (e.g., filesystem-based, Spark-based, or cloud-native), and user-level interfaces (Jupyter notebooks or graphical user interfaces) without needing to change these tools’ internal code. This can help improve scalability, resource efficiency, and costs, as well as DL user productivity and portability across tools and environments. 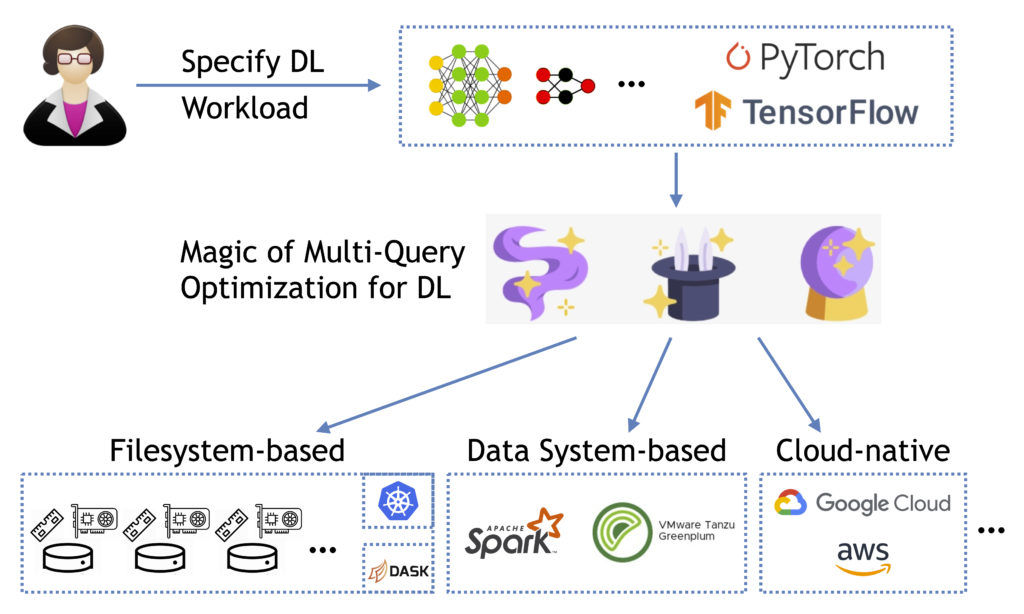
Kumar cites the work of David DeWitt, one of his graduate school mentors at the University of Wisconsin-Madison, as one of the technical inspirations for this work. DeWitt is the pioneer of scalable and parallel relational database systems and scientific benchmarking of database systems.
Kumar believes the ML world sorely needs both of those philosophies–principled approaches to scalability and scientifically rigorous system benchmarking–and aims to redress these research gaps while also accounting for the different mathematical properties and practical operational constraints of ML workloads.
Kumar’s talk at CIDR was well-received by the database community as an example of the marriage of classical database ideas with modern ML systems to help democratize ML beyond technology companies.
Cerebro is supported in part by a Hellman Fellowship, the NIDDK of the NIH, an NSF CAREER Award, and two VMware gifts. Cerebro techniques have already been adopted by Apache MADlib, an open-source library for scalable ML on RDBMSs.
VMware is putting the technology in front of their enterprise customers. Their researchers presented a talk on their adoption at FOSDEM. Kumar’s students also integrated Cerebro with Apache Spark, a popular dataflow system. Zhang and Nakandala gave a talk on this integration at the Spark+AI Summit, one of only a handful of academic research-based talks at that popular industry conference. The first full research paper on Cerebro was published at VLDB, a premier database conference, with Nakandala presenting the talk. Nakandala and Zhang have also presented progress updates on Cerebro at the CNS Research Review in 2019 and 2020 and received feedback from CNS industry partners.
Kumar’s group has open-sourced the whole Cerebro platform to enable more practitioners to benefit from this technology. It is being used for UC San Diego Public Health research on terabyte-scale labeled datasets. The DL models built using Cerebro are being used to monitor various cohorts’ physical activity levels, including people in assisted living facilities and people with obesity, to help them live healthier lives. This project was funded by NIH NIDDK, demonstrating the growing importance of scalable data analytics and ML/DL in healthcare.
Looking ahead, Kumar has also started collaborations with other scientists to use Cerebro to help them scale DL for their analyses in materials science, political science, and neuroscience. Kumar believes DL’s growing popularity in domain sciences and other non-commercial pursuits makes his vision of democratizing DL systems more urgent, helping all users benefit.